TuneFinder: AI-Powered Music Discovery for DJs
Thousands of new releases processed every week. Scored against a taste profile built from years of actual mix history. The shortlist arrives in Discord on Monday morning, automated and self-hosted, for roughly £10/month in LLM costs.
The Problem
Crate digging is central to DJing. It is also, in 2026, a grind. Thousands of new releases land every week across Beatport, Juno Download, Bandcamp, Traxsource, and a dozen other platforms. The process is monotonous: open a genre page, scroll, click a track, listen for 20 seconds, decide if it fits, move on. A productive session might yield five to ten tracks worth buying.
Covering D&B, Breakbeat, UK Bass, UK Garage, House, and Electronica means tracking a wide scene. No single platform surfaces everything. And all of them optimise for what is commercially popular, not what fits a specific taste.
The Insight
Years of mixes on SoundCloud already contain a detailed record of taste. Every track chosen to play, in any context, is a data point: artist, genre, BPM, energy level, all of it encoded in the tracklists.
Describing preferences to an AI in abstract terms is the obvious approach. It is also the wrong one. Point the system at what has already been played and let it infer the profile from real behaviour. The mix history is the taste profile.
System Architecture
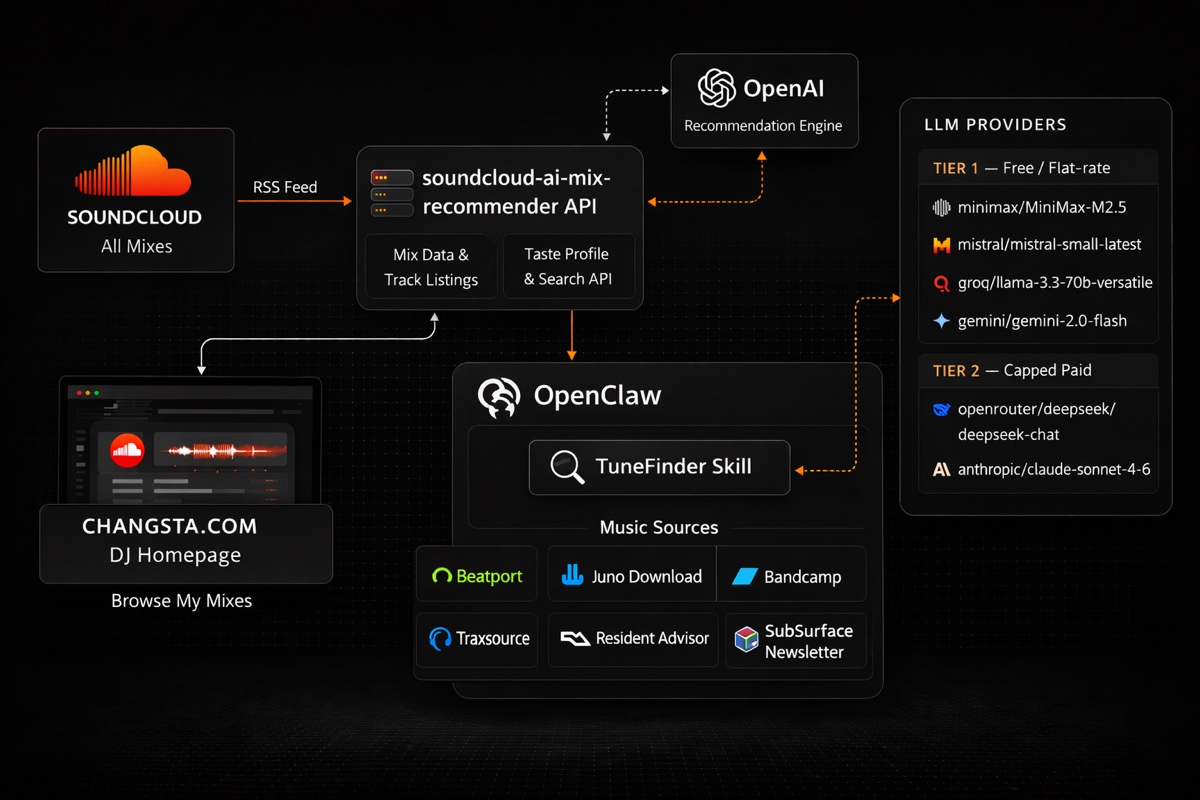
TuneFinder has two halves: a taste layer that reads mix history and builds an artist profile, and a discovery layer that scrapes music platforms for new releases. These meet in a ranking pipeline, which feeds a two-stage LLM report, orchestrated by a self-hosted AI agent.
- Known-track filterFuzzy match removes already-owned tracks, including variant suffixes
- Deduplication & cross-source mergeTracks appearing on multiple sources are merged; all metadata retained
- Ranker7 weighted signals - artist affinity, label match, chart position, cross-source validation, genre, recency
- Stage 1 LLM - reason enrichmentMiniMax M2.7 with Groq / Gemini fallback - writes a one-sentence reason per track
- Stage 2 LLM - report writingClaude Sonnet - produces the full Discord-formatted weekly report
- OpenClaw (Mr Robot)Self-hosted AI agent · orchestration, scheduling, interactive layer
Building the Taste Profile
TuneFinder needs two things: which artists to look for, and which tracks to exclude. Both come from a .NET Web API built at changsta.com, deployed to Azure App Service.
The API maintains a structured catalogue of every published SoundCloud mix by merging two sources: a historical catalogue in Azure Blob Storage, and SoundCloud's RSS feed for recent mixes. New mixes discovered via RSS are automatically written back to the blob, so the catalogue grows without manual intervention. Results are cached in-memory to avoid hitting both sources on every request.
One endpoint returns a deduplicated track list across all mixes. Each entry carries a recurrenceCount (how many different mixes include that track), which becomes the primary signal.
From that, TuneFinder builds an artist profile for every artist in the history. Collaborative credits are split individually. Play count is weighted by recurrence: an artist whose tracks appear across four mixes contributes more weight than one played once. That naturally separates genuine preferences from passing experiments.
The result is a dictionary of 1,000+ artist profiles, each with a weighted play count and associated genres. Alongside it, a known-track exclusion set fingerprints every track already played, so the system never recommends something already owned.
Finding New Music
Six source fetchers run in parallel every week. The goal is breadth: no single platform covers the full scene, so casting a wide net and cross-referencing produces a much stronger signal than relying on any one store's algorithm.
- Beatport - genre top-100 charts (D&B, Electronica, UKG, Breaks, five house sub-genres). Chart position, BPM, and label data come from the embedded
__NEXT_DATA__JSON (the same hydration payload that powers the page) rather than scraping HTML, which is far more stable. - Juno Download - weekly bestsellers charts per genre, scraped for chart position, BPM, label, and artist.
- Bandcamp - queried by genre tag to surface independent releases that often appear here before hitting the main stores.
- Traxsource - genre landing pages for house and techno releases from the more underground end of the market.
- Resident Advisor - catches releases from labels that operate entirely outside the Beatport ecosystem.
- Subsurface Selections - a curated newsletter archive. Every track mentioned is treated as a recommendation from a trusted human curator, giving it additional weight as a cross-validation signal.
A track on Juno's chart and Bandcamp is a stronger signal than one platform alone. Cross-source agreement ends up being the pipeline's most reliable quality filter.
The Ranking Pipeline
After fetching, ~4,000 raw candidates pass through several stages. First, deduplication: tracks appearing on multiple sources are merged into a single candidate, retaining all source metadata. Then the known-track filter removes anything matching the play history. A history filter also excludes tracks already recommended in previous reports.
Each surviving candidate is scored against weighted signals:
| Signal | Weight | Trigger |
|---|---|---|
| Known artist | 3.0 × play count | Artist in mix history |
| Recurring artist | +2.0 | Artist with 3+ plays in history |
| Label match | +2.5 | Label associated with known artists |
| Chart position | up to +1.5 | Position 1–100, decays linearly |
| Cross-source | +1.0 | Track appeared on 2+ sources |
| Genre match | +0.5 per tag | Genre in known set |
| Fresh release | +0.5 | Released within the last 30 days |
The chart position bonus matters. A track at #1 on the Juno chart gets the full 1.5 bonus, decaying to zero at position 100. This surfaces music the broader scene considers significant, not just what is algorithmically new.
Tracks that score well but miss the weekly cut are held in a persistent candidate pool and re-evaluated in future runs. A track appearing across multiple weeks without being recommended gradually accumulates credibility.
Top candidates split into four sections: Top Picks, Label Watch, Artist Watch, and Wildcards, with per-artist and per-genre caps to keep variety.
The weights are based on intuition and manual experimentation. The architecture accepts new signals without restructuring the pipeline, which matters; the scoring will keep changing as I learn which signals actually predict what ends up getting played.
Two-Stage LLM Report
Scored candidates are a spreadsheet, not a report. A two-stage LLM pipeline fixes that.
Stage 1: Reason enrichment
A fast, cheap model (MiniMax M2.7, with Groq or Gemini as fallback) gets all shortlisted candidates with their scoring signals and writes a one-sentence reason per track. The output is specific: "You play Calibre regularly and this is his first EP in two years." Not a generic summary.
Stage 2: Report writing
Claude Sonnet gets the enriched candidates and writes the full Discord-formatted report. The prompt asks it to write like a respected record shop selector, opinionated, concise, scene-aware. The system prompt encodes enough genre context that it knows the difference between a peak-time roller and a warm-up cut.
OpenClaw: Orchestration Layer
TuneFinder started as a Python script run manually from the terminal. It worked, but it was fragile - SSH to the server, activate the venv, remember the flags, babysit the output. Silent failures were hard to track down.
OpenClaw is a self-hosted AI agent platform running on a Mac Mini M1. Not a chatbot. It executes shell commands, calls APIs, manages scheduled tasks, and keeps persistent context about its environment.
TuneFinder is registered as a shell skill with a wrapper that defines the command, the schedule (Monday 8am), the Discord output channel, and the failure behaviour. If the script exits non-zero or produces no output, OpenClaw posts a failure notice to a separate #logs channel. If a source fetcher breaks because a platform changes its page structure, it surfaces immediately.
On-Demand Reports
Because TuneFinder is exposed as a skill, it can be triggered conversationally. On Discord, @mention Mr Robot and say "run a mix prep report for drum and bass." OpenClaw maps the intent to the right skill, executes the pipeline with the appropriate genre filter, and posts results back to the same channel. No terminal, no flags.
Cost-Aware LLM Cascade
Running an agent 24/7 gets expensive if every interaction hits a frontier model. OpenClaw uses a tiered cascade, priority-ordered by cost:
- Casual interactions: Gemini 2.5 Flash → Groq Llama 3.3 70B → Mistral Small (free tier)
- Higher-demand tasks: MiniMax M2.7 (flat $10/month subscription)
- Report writing: Claude Sonnet (reserve - invoked only for Stage 2 output)
Why a Mac Mini Under a Desk
The Mac Mini M1 draws about 7 watts at idle. It runs 24/7 and costs almost nothing beyond electricity. Running locally avoids paying for a cloud VM and keeps the whole thing simple. That is a deliberate architectural choice, not a limitation.
The worst realistic failure is a missed weekly report, which does not justify the operational overhead of cloud infrastructure or container orchestration. The complexity budget is better spent improving the pipeline logic than building resilience the system does not really need.
Results
TuneFinder surfaces 15–20 relevant tracks per week from ~4,000 candidates, and growing as new sources are added. The known-artist signal is the strongest predictor by some margin. If an artist who gets regular play has a new release, it surfaces immediately. Cross-source agreement is the most reliable quality filter: a track independently validated by Juno's chart buyers and Bandcamp's independent listeners is almost always worth a listen.
I can trigger a genre-specific mix-prep report via Telegram on demand, useful when building a set and wanting to narrow the focus.
The label watch section has introduced several labels now followed directly. The system inferred label relevance from play history without any explicit label list being provided. That was a surprise.
With OpenClaw, there is nothing to remember. The report arrives in Discord every Monday morning.
A Reusable Pattern
The most interesting outcome is not TuneFinder itself. It is that the architecture turned out to be a reusable template.
OpenClaw already runs a second automation called Signal Monitor that tracks ~25 companies in the Exhibitions & Events industry for hiring, product, M&A, and expansion signals. It uses the same two-stage LLM pipeline (cheap model for data extraction, Claude Sonnet for report writing), the same Discord delivery model, and the same OpenClaw skill wrapper with error routing and scheduled execution.
What's Next
- Richer metadata from existing sources - platforms like Beatport hold BPM, musical key, label, and release date, but API access is gated. The path forward is extracting more from existing
__NEXT_DATA__payloads and cross-referencing fields between sources so merged candidates carry richer metadata. - Broader source coverage - SoundCloud reposts from followed artists, Spotify Release Radar, and label-direct Bandcamp pages are signals currently missed. Each new source adds noise, but also strengthens the cross-source validation that is already the ranker's most reliable quality filter.
- Closing the feedback loop - there is already an implicit feedback signal built in: when a track is bought and played in a mix, it is ingested back into the taste profile. The system already learns from purchases but it just does not yet know which tracks were originally its recommendations. Tagging recommended tracks would let the pipeline measure its own hit rate and adjust scoring weights over time.
Tech Stack
Building something similar?
TuneFinder started as a personal tool, but the pattern it uses is domain-agnostic: aggregate from multiple sources, score and filter, deliver a readable report to where you already are.
If you are working on something similar (industry monitoring, research aggregation, personal tooling with a real ranking problem), feel free to get in touch.