MixLab: AI-Powered Mix Curation for DJs
A curation assistant for DJs who have outgrown their own collection. It takes a Rekordbox library of 2,500+ tracks, cross-references it against a live play history, and generates multiple fully-sequenced mix concepts from unexplored material. Each concept comes with a harmonic arc, energy curve, opener and closer rationale, and a Rekordbox playlist file ready to load directly into CDJs. A full run against a house genre pool of 336 unplayed tracks produces six named, narrative-driven concepts in under ten minutes.
The Problem
There is a specific kind of paralysis that comes with having too much music.
A DJ who has been buying records consistently for years will end up with a collection that eventually exceeds what they can hold in their head. At 500 tracks it is manageable. At 1,000 you start to forget things. At 2,500 you are effectively flying blind. You know the records you reach for out of habit. Everything else sits in the crate, purchased and tagged and never played.
The instinct is to keep buying. The real problem is curation.
Creativity has the same problem. Building a coherent set is a genuine act of musical reasoning: sequencing tracks, managing energy from opener to closer, deciding when to surprise and when to sustain. It also corrodes with familiarity: a DJ who knows their records well tends to reach for the same combinations, the same trusted paths through the collection. MixLab works on both. It identifies what has not been played, and applies a structured creative process to that unexplored material.
Where It Sits in the Ecosystem
MixLab is the second tool in a two-part workflow that begins with TuneFinder.
TuneFinder answers the question: what should I buy? It monitors six release platforms weekly, scores candidates against a behavioural taste profile derived from mix history, and surfaces 15-20 relevant tracks.
MixLab answers the question that comes next: what should I play, from what I already own?
TuneFinder populates the Rekordbox library. MixLab curates it. Together they form a closed loop: discover, collect, curate, perform.
System Architecture
The pipeline runs through several distinct phases on each execution.

- Collection ParsingReads Rekordbox XML via lxml · extracts BPM, Camelot key, genre · excludes tracks missing BPM or key · handles D&B half-BPM edge case
- Play History Cross-ReferencePulls full Changsta API catalog · normalised matching (unicode, feat. stripping, punctuation removal) · outputs unplayed pool grouped by genre
- Collection Overview & Genre ClusteringFull availability table across collection · genre map (8+ Rekordbox tag variations → consistent labels) · BPM median filter · outlier section for unmapped tags
- Harmonic Pre-SortGreedy Camelot wheel walk · finds next harmonically compatible track (adjacent or same position) · prefers lower BPM candidate on ties
Phase 1: Collection Parsing
Rekordbox exports its library as XML. MixLab reads this file directly using lxml, pulling out artist, title, BPM, key (in Camelot notation), genre, and track ID. Any track missing BPM or key data is excluded, since harmonic sequencing requires both. One known edge case is handled automatically: some Drum & Bass tracks get tagged at half their true BPM in Rekordbox. The system detects these by genre and doubles the value.
Phase 2: Play History Cross-Reference
The Changsta API holds a paginated catalog of every track played in a recorded mix. MixLab pulls this down in full - typically 1,200+ entries spanning a decade of mixes - and filters the collection against it. Matching uses normalised comparison: unicode normalisation, featured artist stripping, punctuation removal. This is necessary because track titles often differ slightly between the Rekordbox tag and the mix catalog entry (feat. vs ft. vs featuring, that kind of thing). The result is a filtered pool of genuinely unplayed tracks, grouped by genre.
Phase 3: Collection Overview and Genre Clustering
Before any genre-specific work begins, MixLab prints a full availability table across the entire collection. For each genre, it shows how many tracks are in the library and how many are unplayed, rendered as a simple bar chart in the terminal and Discord report. This gives an at-a-glance picture of where the collection is concentrated and which genres might need more attention or buying. A genre sitting at 95% played is telling you something different to one sitting at 55%.
The report also surfaces a separate section of outliers - tracks whose Rekordbox genre tag does not map to any known label. These are not discarded quietly. Seeing them listed is useful in practice, because it often reveals tagging inconsistencies that have crept in over years of importing from different sources. A track tagged "House;Downtempo;Leftfield" or left with a blank genre is easy to miss in Rekordbox itself; surfacing it here makes it easy to go back and fix. Getting the tags right means those tracks will be picked up correctly on the next run.
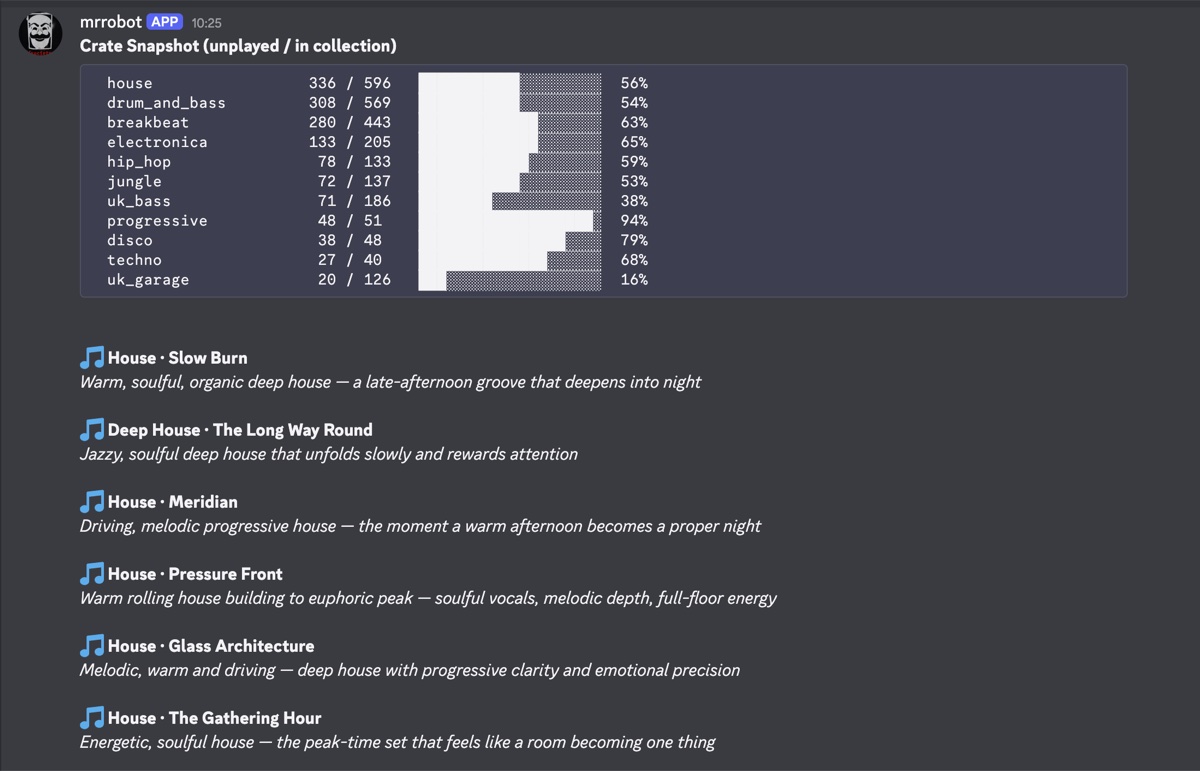
The genre map itself translates Rekordbox's inconsistent free-text tags into consistent labels, so house covers eight distinct variations. Within each cluster, a BPM median filter removes any tracks sitting more than 6 BPM outside the group median. Outliers that share the requested genre character (four or more) are passed to the LLM pipeline as a "Misc" pool rather than dropped entirely.
Phase 4: Harmonic Pre-Sort
Before anything hits an LLM, tracks in each cluster are pre-sorted by Camelot wheel compatibility. The algorithm walks the list: from the first track it finds the next harmonically compatible one (adjacent or same position on the wheel, same or relative mode), preferring the lower BPM candidate where there is a choice. By the time the LLM receives its input, it is already a musically coherent sequence rather than an arbitrary list.
The Two-Stage LLM Pipeline
The two stages do different jobs, and that distinction matters for cost as much as for quality.
Stage 1: Technical Shortlisting (Provider Cascade)
The first stage is purely analytical. Given up to 40 tracks, the model groups them into 2-3 candidate pools of 15-25 tracks each, based on a shared BPM centre and harmonic character. It is told explicitly not to make ordering or editorial decisions - its job is pre-screening, not curation. The output is a JSON array of shortlists with rough descriptive titles ("Deep 122 BPM / 4A-7A Pool") and a one-line sonic mood.
This stage runs against a provider cascade: MiniMax M2.7 first, then Groq (Llama 3.3 70B), Gemini 2.5 Flash, OpenRouter (DeepSeek), and Claude Sonnet as a last resort. The cascade prioritises cost and speed. MiniMax and Groq are fast and cheap; the Anthropic fallback exists to keep the pipeline running if everything else fails, not because it is the preferred choice here. If a provider times out or returns malformed JSON, the next one is tried without any intervention needed. MiniMax's reasoning models emit inline <thinking> blocks that get stripped before JSON parsing.
Genre pools larger than 40 tracks are chunked and processed in batches, with the resulting shortlists merged at the end.
Stage 2: Creative Curation and Narration (Anthropic, fixed)
The second stage is where the actual curation happens. All candidate shortlists from Stage 1 are sent - capped at six, ranked by pool size - to Claude Sonnet in a single call. This stage has no fallback. The quality of output here justifies both the cost and the hard dependency.
The system prompt instructs the model to work as a mix curator. For each shortlist it has to select the best 8-12 tracks from the pool, sequence them as an intended play order, design a deliberate energy curve across the set (tension, build, peak, release, landing), and justify the editorial choices it makes. The instruction is explicitly not to optimise only for BPM and key compatibility. The goal is flow, memorability, and emotional payoff. Bigger key jumps and tempo pivots are encouraged when they serve the journey.
Each concept in the output includes:
- A creative name, not the pool label from Stage 1
- Track order with Camelot key and BPM annotated inline
- An arc description covering the emotional journey, structural logic, and specific moments worth naming
- Opener rationale: why this track works first
- Closer rationale: why this track works last
- Standout transitions: 1-3 specific moves called out with precise context
- Assumptions: what was inferred from metadata where audio analysis was not possible
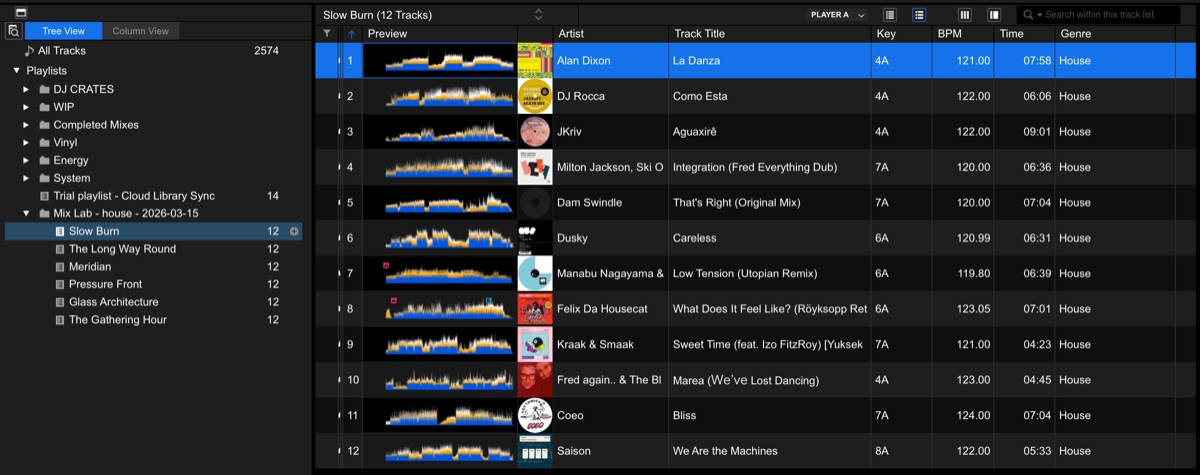
This is a set about patience and warmth. It starts in the late-afternoon light, organic, jazzy, unhurried, and slowly, almost imperceptibly, finds its spine. No rush, no shortcuts. The energy earns every degree it gains.
- 1 Alan Dixon - La Danza
- 2 DJ Rocca - Como Esta
- 3 JKriv - Aguaxirê
- 4 Milton Jackson, Ski Oakenfull - Integration (Fred Everything Dub)
- 5 Dam Swindle - That’s Right
- 6 Dusky - Careless
- 7 Manabu Nagayama & Soichi Terada - Low Tension (Utopian Remix)
- 8 Felix Da Housecat - What Does It Feel Like? (Röyksopp Return To The Sun Remix)
- 9 Kraak & Smaak - Sweet Time (feat. Izo FitzRoy) (Yuksek Remix)
- 10 Fred again.. & The Blessed Madonna - Marea (We’ve Lost Dancing)
- 11 Coeo - Bliss
- 12 Saison - We Are the Machines
Opens with three consecutive 4A tracks (La Danza, Como Esta, Aguaxirê) that share a Latin-tinged, percussion-forward warmth and let the room settle into the groove without demanding attention. The pivot to 7A via Integration is the first emotional shift: it broadens the harmonic palette and introduces something more melancholic. Dam Swindle’s That’s Right holds that 7A space with more swagger. Dusky’s Careless and the Soichi Terada dub pull the energy inward and hypnotic. This is the set’s most intimate moment, the valley before the climb. Felix Da Housecat’s Röyksopp remix is the inflection point: same key, but the production lifts the ceiling. Kraak & Smaak’s Yuksek remix adds vocal soul and a sharper rhythmic edge. Marea is the emotional peak; its weight and cultural resonance land differently after this journey. Coeo’s Bliss resolves into something euphoric and clean. Saison - We Are the Machines closes as a statement: driving, machine-like, but earned.
La Danza is the perfect slow-burn opener: unhurried, percussion-led, melodically restrained. It signals warmth and craft without showing all its cards. The room can breathe into it.
We Are the Machines provides resolution through contrast; after the organic, soulful middle section, its mechanical drive feels like a final exhale, a reminder that this is still a dance floor. It closes the loop without sentimentality.
A deliberate key jump that shifts the emotional register from groove-forward to introspective. The drop in BPM is almost imperceptible but the harmonic move opens the set up.
Same key, significant BPM lift; this is where the set quietly accelerates. The Terada dub’s dreamlike quality makes the Felix track feel like waking up.
Marea’s emotional weight needs a release valve. The jump to 7A and Bliss’s cleaner, more euphoric production is that release; it doesn’t deflate the moment, it transforms it.
Susumu Yokota - Genshi (5A, 120) was excluded despite its beauty; its experimental texture would break the organic groove logic of the opening section. Radio Slave - The Lunatics was excluded as too dark and industrial for this set’s character. Eelke Kleijn / Distance (8A) was excluded to avoid an awkward key outlier mid-set. Coeo - Sorry for the Late Reply (4A, 123) was considered for the opening run but felt redundant alongside La Danza and Como Esta. David Penn - The Heat was excluded as too functional/peak-time for this set’s emotional register.
The prompt specifies the tone as opinionated, musical, honest, no marketing language, no filler. The outputs reflect that. A concept called "Slow Burn" opens with Alan Dixon's La Danza and explains in plain terms exactly why the key jump from 4A to 7A at the midpoint earns its emotional shift. "Pressure Front" names the Trevino remix of Goldie's Inner City Life as "a house music weapon" and accounts for why it holds up at 127 BPM within the 8A cluster. The reasoning is specific to the actual tracks in the pool, not generic advice dressed up in music-sounding language.
Prompt Engineering
The hard part of writing this prompt had nothing to do with LLM mechanics. It was deconstructing what DJs do. What does an opener do that a second track cannot? What makes a closer feel like an ending rather than just the last thing that played? Why does a harmonic jump that looks wrong on paper sometimes feel inevitable on a dancefloor? These are not questions DJs typically answer. They just play.
Getting useful output meant turning that instinct into explicit rules, without killing the creativity in the process. Most AI music prompts fail here: they describe genre characteristics and energy arcs in the abstract, and get back something technically correct and musically inert. The prompt evolved through that specific failure, each iteration stripping one more layer of assumption to find the logic underneath.
A ceiling remains. Stage 2’s output quality is bounded by the LLM’s world knowledge of individual tracks. The Assumptions section makes this visible; it does not fix it. The obvious next step is richer input: cue point data as a proxy for intro and outro length (it is already in the Rekordbox export), energy ratings, colour tags. Less inference from a track name, more signal from the file.
Output and Delivery
Rekordbox XML Export
The curated track IDs from Stage 2 are matched back against the raw Rekordbox XML. MixLab generates a single merged export file with a shared track collection and all concepts as named playlists, nested inside a dated folder ("Mix Lab - house - 2026-03-15"). Load it into rekordbox and each concept appears as a ready-to-use playlist in the intended play order.
Discord Delivery
The full text report and the Rekordbox XML are sent to Discord via webhook. The report arrives as a formatted message and the XML as a file attachment. The output is on any device immediately, archived in the channel automatically, with no need to touch a terminal to retrieve it.
Results
A house genre run, in numbers:
- 2,574 tracks parsed from the Rekordbox library
- 1,224 played tracks cross-referenced from the Changsta API
- 336 unplayed house tracks identified across 8 Rekordbox genre tags
- 6 named, sequenced mix concepts generated, each with 10-12 tracks
- Total runtime: 8 minutes 9 seconds, most of which is Stage 2 LLM time
Six concepts, genuinely distinct in character: from a jazz-inflected deep house arc built around patience and warmth to a high-pressure peak-time set anchored by Inner City Life and The Blessed Madonna. Each draws entirely from music that is owned but unplayed. Each loads directly into professional DJ software.
The creative brief, the arc, the transition rationale: these are starting points, not instructions. Which concepts are worth pursuing, which tracks to swap, how a set unfolds on the night: those stay human decisions. MixLab expands reach into the collection. The taste required to use it is still yours.
A useful edge case: when Stage 2 identifies a concept where the unplayed pool is too thin for a proper set, it says so directly and flags how many tracks are missing. That closes the loop. MixLab points at what to go and find.
In the Booth
I took the Slow Burn concept and played it as an actual mix. These are my honest thoughts.
What Worked
The overall journey held up. The set had a real shape to it and I enjoyed playing it. What I got most from it was tracks I had completely forgotten about, which is the whole point of the tool.
Where It Missed
Reading tracks from their names. Alan Dixon’s La Danza and DJ Rocca’s Como Esta were described as Latin-tinged and percussion-forward. In practice, La Danza is quite psychedelic and Como Esta is more warehousey. The AI almost certainly picked that up from the track names, which both sound Latin. It had no way to know what they actually sound like. This is exactly the limitation the Assumptions section exists to surface, and it is a direct argument for enriching the Track model with better metadata. A genre tag or energy rating would have caught this. A track name cannot.
The vocal clash. The Felix Da Housecat Röyksopp remix into the Kraak and Smaak Yuksek remix had clashing vocals, something you would never know from a tag or a title. The prompt now explicitly flags this risk in the Assumptions section when arrangement data is unavailable, but flagging a risk is not the same as resolving it. In practice it forced an interesting solution: using STEMs to isolate and blend the two vocal layers, which ended up working quite nicely. A limitation that led somewhere good.
Getting the closer wrong. Saison’s We Are the Machines was predicted to be a driving, machine-like closing statement. It is a chilled, vibey tune. It worked as a closer, but for reasons the AI did not anticipate. This is the world knowledge ceiling in action: the prompt can define what a closer needs to do. It cannot verify whether a specific track does it.
Something I Did Not Expect
I skipped Marea by Fred Again and The Blessed Madonna. Not because it was in the wrong place (the sequencing was fine) but because listening to it in context I realised I was not into it anymore. MixLab surfaced it because I had never played it in a recorded mix. Useful, just not in the way I expected: it flagged a track that probably should not be in my collection anymore. The tool found a gap I did not know I had.
Tech Stack
Also in the MixLab pipeline
- MixLab: Playlist Completion
Extends MixLab for sets that already have a direction. Classifies seed tracks by tier, generates three scored variants (practical, balanced, and adventurous) and delivers the winner directly to Rekordbox.
Building something similar?
MixLab is a specific tool, but the underlying approach (structured pipeline, staged LLM, output that lands somewhere immediately useful) applies to a wide range of problems. If you have something in this space and are trying to figure out how to build it, I am interested in that conversation.